Abstract
We explore prediction of urban pedestrian actions by generating a video future of the traffic scene, and show promising results in classifying pedestrian behaviour before it is observed. We compare several encoder-decoder network models that predict 16 frames (400-600 milliseconds of video) from the preceding 16 frames. Our main contribution is a method for learning a sequence of representations to iteratively transform features learnt from the input to the future. Then we use a binary action classifier network for determining a pedestrian’s crossing intent from predicted video. Our results show an average precision of 81%, significantly higher than previous methods. The model with best classification performance runs for 117 ms on commodity GPU, giving an effective look-ahead of 416 ms.
Pratik Gujjar and Richard Vaughan
Predicting a Future
Typically, three-quarters of a second are needed to see a hazard and to decide to stop. Three-quarters more of a second are needed to actuate the brakes to stop a vehicle. An early prediction of a potentially hazardous action, could add precious time before one decides to act.
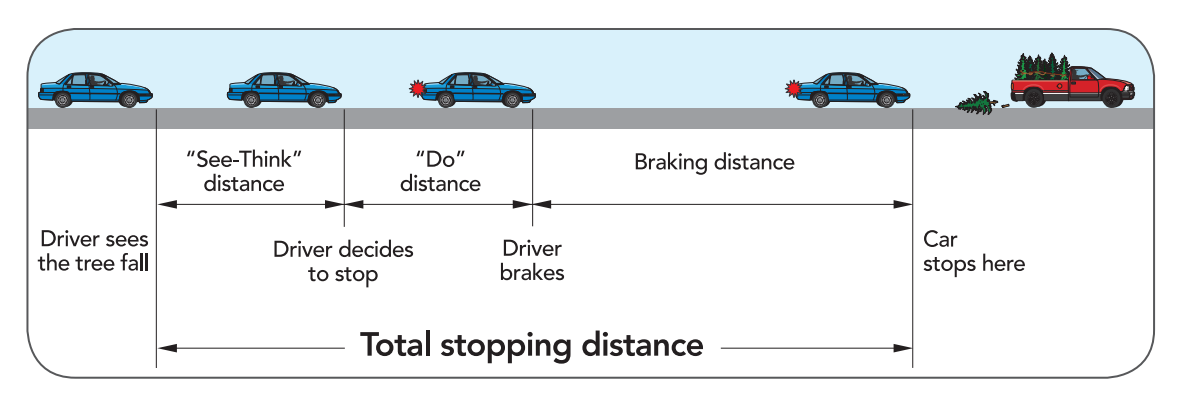
Commonly expected crossing behaviour Standing-Looking-Crossing and Crossing-Looking only account for half the situations observed. In more than 90% of the JAAD dataset, pedestrians are observed to use some-form of non-verbal communication in their crossing behaviour. The most prominent signal is to look at oncoming traffic.
 |
 |
Without contextual knowledge, the pedestrian in the example below is likely to be predicted as continuing to walk across. The knowledge of the stationary car adds the information that the pedestrian is very likely to stop before it.

Experiments
We use the JAAD dataset [paper] consisting of 346 high resolution videos in pedestrian interaction scenarios. We train our encoder-decoder stack to optimize for a combination of l1 and l2 losses. The losses are calculated between the N pixels of T predicted frames y’ and ground truth frames y. For video prediction experiments we set N = 128 × 208 and T = 16 frames. We train three kinds of models for future prediction: a fully convolutional model (Conv3D), a recurrent decoder model (Segment) and a residual encoder-decoder model (Res-EnDec). We perform ablation studies on our Res-EnDec model to determine the importance of the residual connections, dilated convolutions and reversal of image data.
| History + Ground Truth | History + Prediction | |||
| Conv | ||||
 |
 |
|||
| Segment | ||||
 |
||||
| Res | ||||
 |
||||
| Res-EnDec | ||||
 |
||||
| Conv | |
 |
 |
| Segment | |
 |
|
| Res | |
 |
|
| Res-EnDec | |
 |
Crossing Intent
The task of action recognition is motivated by the idea that by looking ahead in time, we could react to a hazardous pedestrian interaction a little earlier, with safety benefits. We do this end-to-end by appending a binary action classifier to our future video generator. In this task, we want to learn to predict a pedestrian’s crossing intent across a multitude of crossing scenarios and behaviours.
| History + Ground Truth | History + Prediction |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
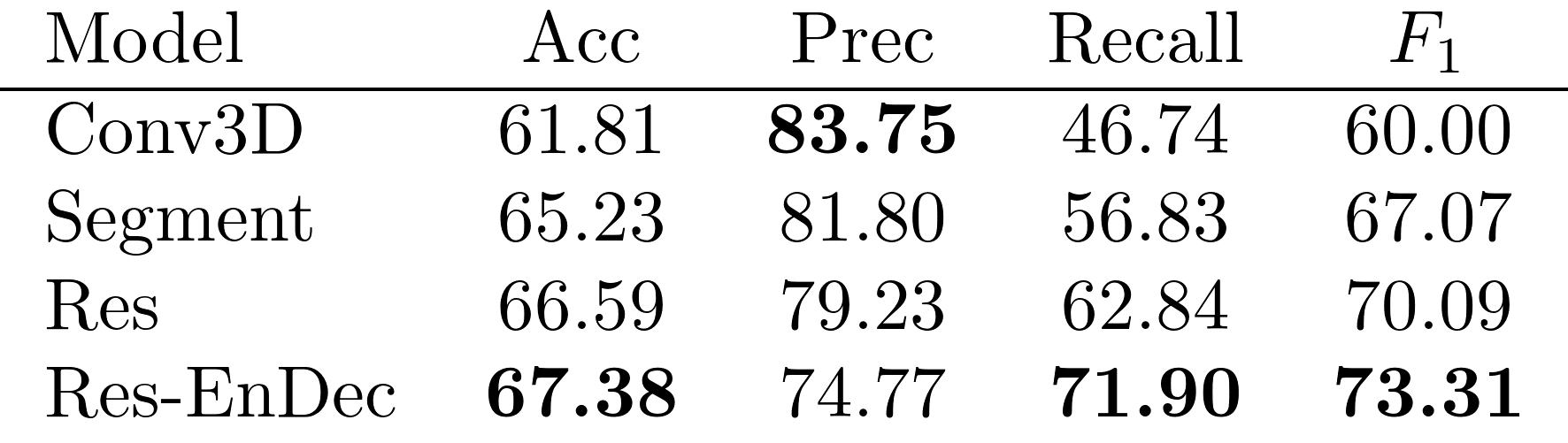
Classification Performance

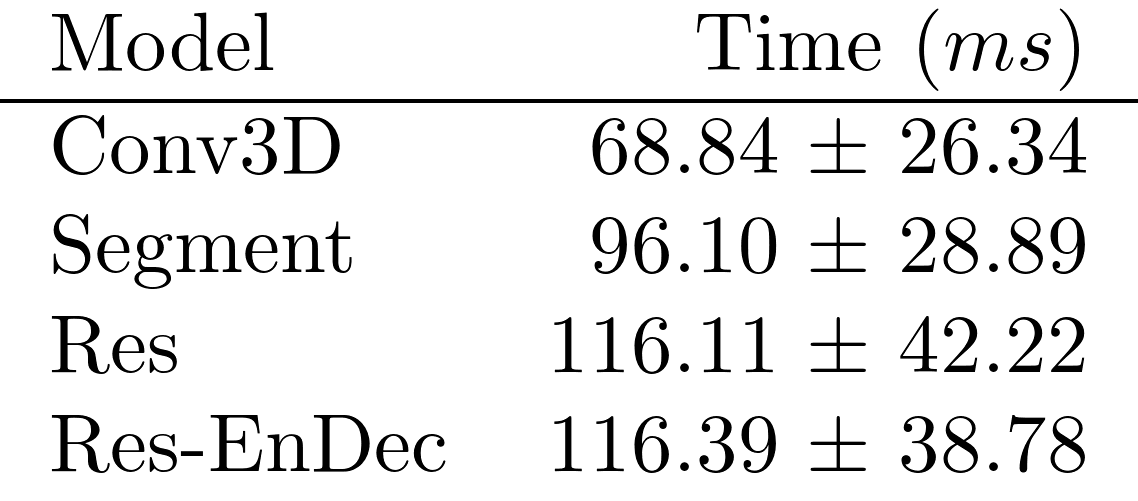
Run-Time Analysis